模块化的应用程序是由分布式团队开发出来的独立组件组成的。这些独立的组件通常都会提供一个自己的API,当然在具体执行的时候,也需要第三方组件的API或者其他功能才能保证正确运行。例如,Tomcat服务器需要Java运行时实现。同样,标准的C++模板库也需要libc,这样才能调用printf方法。如果使用了大量的组件,那么面临的最大问题就是能否看清整个应用的全貌。只有理解了整个系统以后,才能理清楚模块间的交互关系。在上一节中,我们可以看到一个组件的API只会把其最重要的功能给暴露出来,大部分情况下,用户无需关注其内部的实现,只需要集中精力了解API即可。但如果系统包含成千上万个组件的话,光是组件API的信息就会非常多,很难无绪地处理。所以我们来看看能否找到一些可行的方式,在不需要深入了解所有组件的情况下,也能把组件整合在一起来构建可用的系统。
在设计API时,第一课也是最重要的是:给自己的组件起个漂亮的名字。这些名称必须是独一无二的,能够根据该名称在整个系统中查找到相应的组件,而且这个名字应该尽量做到让用户闻其名知其意。对Linux Kernel来说,其中kernel这个词就是一个很好的名字;libc是C语言的基础库,这个名字也算不错;org.netbeans.api.projects是NetBeans平台上的一个支持项目结构的组件,这个名字堪称完美。一般来说,现代的所有组件都有一个名称,因此要开发新组件的话,也很自然地应该先给它起个名字。但深入地考虑一下就会发现,所谓的名称,其实只对人有意义,对于机器来说,无论阿猫阿狗哪个名字都无所谓。对于机器来说,任意一个16进制的名字都可以,哪怕是0xFE970A3C429B7D930E。事实上,有些组件的名称还带有人名,这也说明了组件的名称其实主要是针对人而非机器。组件的名字对客户和终端客户很有用,他们可以利用组件的名字了解组件对于供应商和集成商来说,名字也同样重要,有助于他们使用这些组件来构建应用程序。
在知道如何为自己所开发的组件命名以后,还要看一下每一个组件运行的环境。没有哪个组件是在真空中运行的。它需要从周围的环境中取得相应的服务。所以,使用一个组件可能还需要完全了解该组件的环境需求①,搞不好还要深入了解其内部实现才能明确其环境需求,如果运气好一点,通过运行该组件也可以了解其环境需求。但这都不是我们想要做到的“针对性无绪”,因为这样提高了对集成人员的要求,他们在构建一个应用程序之前,还需要了解每一个库的很多细节才行。如果一个库对其用户提出了如此高的要求,那么会严重地阻碍其用户群的发展。事实上,一个库的大部分用户不需要了解该功能库的内部实现。也应该如此,用户可以在不深入了解一个库内部情况的前提下,就能使用库完成自己的工作。通过正确设计和描述每一个独立组件就可以做到这一点。如果一个组件能够自动处理自己所需要的运行环境,那么相应的集成人员在使用该组件时,就能做到尽量无绪,因为相应的环境不需要人为干涉,不需要使用编译器、链接器和集成工具。
在模块化系统中,每一个组件都会提供一些其他组件所需要的信息。组件的设计者需要将这些信息设置进去,或者由打包工具自动处理。例如,RPM安装文件的构建就是如此,Fedora、Mandriva和SUSE这些Linux的不同版本,都使用该格式来创建它们版本的安装包,这些安装包能够自动检查本地动态链接库以查找该软件运行时需要的动态链接库,并自动调整安装包内容以保证能够使用这些动态链接库。不管这些工作是工具自动完成,还是由人工完成,都只需要处理一次就可以了。完成该工作的开发人员应该就是该独立组件的作者,他们知道组件的内部机制,了解组件运行时所需环境,从而正确地列出其依赖的内容。这也是“无绪”的又一个例子:一个工程师多花点时间和精力来列出组件所依赖的内容,而组件的用户,如应用的集成人员或者其他开发人员,则只需要这个组件提供的信息来让工具自动完成相应的工作即可。
配置类路径时的噩梦
纯粹只依赖Java平台来编写Java应用程序的好日子已经一去不复返了。可用于开发Java应用程序的开源软件类库已经很多了,而且还在每天增加。结果,几乎现在每个Java程序都会使用那些已经打包的JAR类库,如Apache Commons、HttpClient、JUnit、Swing部件等。如果要运行这样一个程序,第一件事就是正确设置程序运行时的类路径。直接把这些库都包含在类路径中是一件比较简单的事情,但是每一个库都还有自己额外的依赖库,也需要将这些额外的依赖库也加入到类路径中,如此反复,直到所有的依赖库都加入到类路径中,这样做使得类路径的配置变成了一个噩梦。
我最近有机会使用了FreeMarker,这是一个漂亮的模板引擎,我要把它作为一个类库用在NetBeans的开发中。引入一个freemaker.jar类库文件很容易,但在我尝试检查它的所有类是否成功连接的时候,却觉得非常痛苦。这个JAR包引用了很多别的项目,如Apache ANT、Jython、JDOM和log4j,还有Apache Commons Logging。对于FreeMarker来说,真需要这么多的项目吗?如果没有这些库,那么FreeMarker还能运行吗?如果后者答案是肯定的话,那么又是哪些功能用到了这些库,而且这些功能是否会因为库的缺失而引起系统的崩溃?我不知道,其实我也不想知道,我只希望在使用这个库的时候,能尽量做到无绪,但现在我无法达到这个目标。我现在必须深入研究源代码,找到那些我们在使用FreeMarker时不会调用到的第三方类。我曾经祈祷FreeMarker能够使用某种模块化系统来标识它依赖于哪些内容,如NetBeans Runtime Container就提供了类似的功能。
如果从技术角度来对分布式开发给出一个好的解决方案,那么就是将应用程序模块化。那些非模块化的程序由大量代码组成,然后相互之间紧密地耦合在一起,而模块化程序则可以由很多小的独立代码段②组成。这些小的代码段是独立存在的,且被唯一地标识,通过公开接口的方式供他人使用,每一个代码段还可以正确地描述该代码段所需要的运行环境(比如说第三方组件或部件使用该代码段时,如何准备其环境)。对Linux版本的发行商来说,这种开发方式是可行的,而且也证明了其有效性,可以交由分散的团队按照自己的计划来分别开发相应的模块,然后再由一个管控者将所有的模块集成在一起,这样可以有效地规避时间安排和团队分散的风险。而且这样做可以更好地支持无绪的开发模式:如果开发人员能够将自己所负责部分的依赖正确地描述出来,对系统的集成人员来说,在集成该部分时就不需要了解组件的内部信息了,并且仍然能够成功地构建最终的应用程序。
但现在系统开发面临着新的挑战,要知道,软件开发中的组件并不是静态的,而是会随着时间的推移在不停地向前发展,时刻在变化着。不管这种改变是因为要修正现有的bug,或者增加新的功能,但一个API确实是在不停地变化着,因此仅仅通过一个名字是不能够唯一标识一个API的。为了让很多组件能够整合在一起运行,就必须能正确地标识该组件提供了何种API。
例如,如果一个用Java编写的类引用了String.contains(String)方法,那么这个类可以在Java 5中运行,因为这个方法是从Java 5这个版本开始在String类中提供的。但这个类在Java 6中也可以使用,因为这个版本的Java也提供了这个方法。考虑到Java团队的兼容性处理方式,相信对于最新的Java 7,这个类也是可以使用的。但老版本的Java没有提供这个方法。所以如果使用老版本的Java运行使用了该方法的类,就会出现类无法正确连接的问题③。
事实上,如果开发人员想明确某个类或者某个应用对运行环境的需求,就必须列举该类调用的所有方法,以及它引用的所有类和字段。当然关于依赖的描述信息会非常长、不具有可读性,有时甚至比实际的源代码本身更大。可以简单设想一下,有一个类声明自己需要某一个版本的Java,要求这个版本的Java所提供的java.lang.String,必须有一个构造函数及length和index of这两个方法,而且这个类还实现了java.io.Serializable序列化接口。这样细节的描述已经使得组件超出了无绪的范畴,而本书却一直在强调无绪。尽管一台计算机可以自动检查这些约束关系,但对于人来说,想做到这一点就比较困难了。人们更合适处理一些简单的场景,如使用自然数来标识组件的版本。如果按照这种方式来描述前面的需求,就变成“当前类库要使用Java 5”。
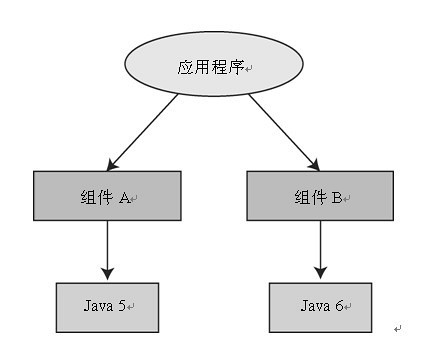
图2-1 应用程序需要一个组件的两个版本同时运行
软件框架设计的艺术——2.2 模块化应用程序

书名: 软件框架设计的艺术
作者: [捷克] Jaroslav Tulach
出版社: 人民邮电出版社
原作名: Practical API Design: Confessions of a Java Framework Architect
译者: 王磊 | 朱兴
出版年: 2011-3
页数: 388
定价: 75.00元
装帧: 平装
丛书: 图灵程序设计丛书
ISBN: 9787115248497